
Vehicle accident prediction
In this project, we were tasked with determining which factors external to the client’s characteristics affect the frequency of car accidents. This was a mock project for an insurance company, during a data science competition.
EDA
The objective of the project was to identify and predict the frequency of car accidents based on exogenous factors such as temperature, weather conditions, time of day, province, type of accident, and holidays.
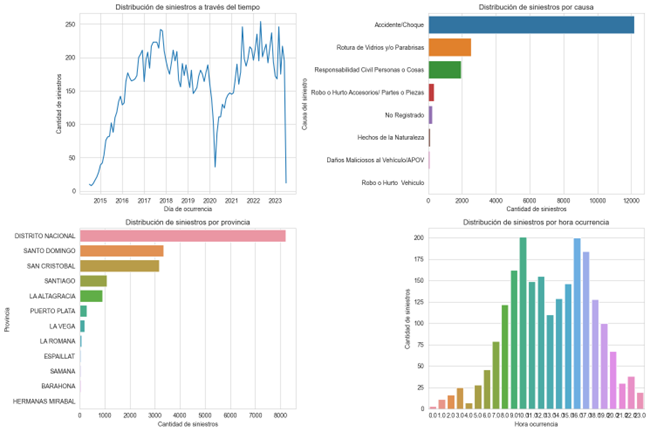
Data sources
We used the Google Maps API to obtain the geolocation data for each of the accidents in the dataset. 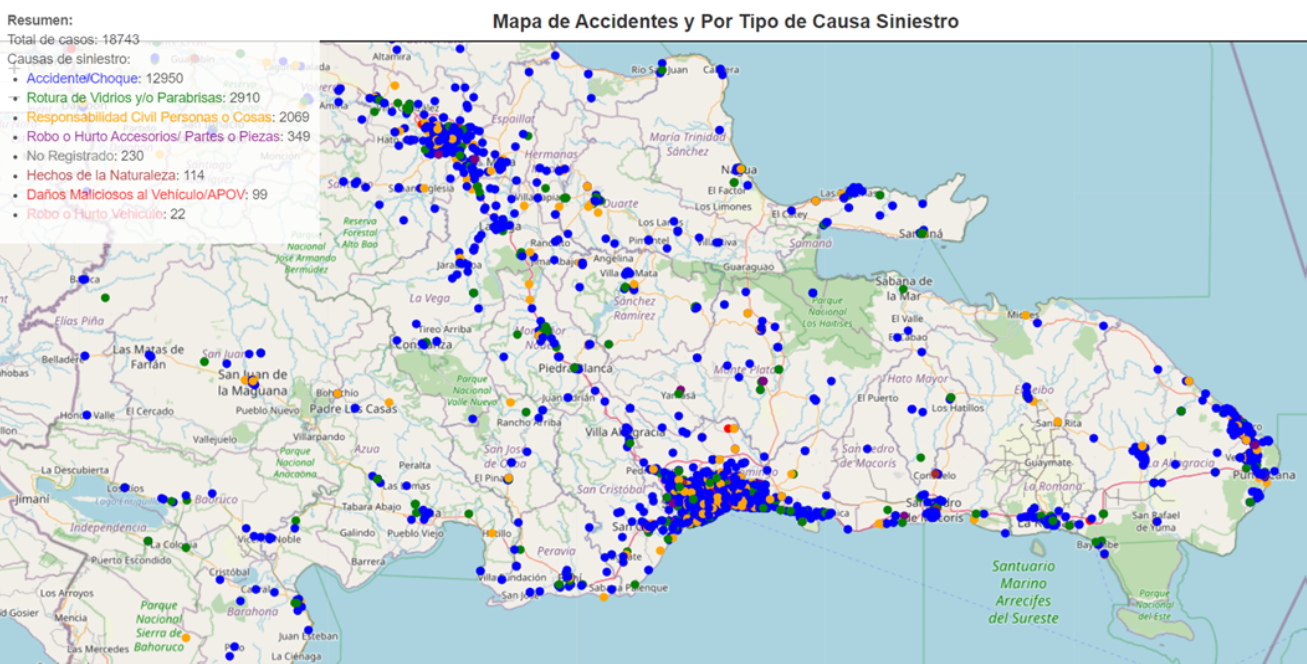
We also connected to the Meteostat JSON API in order to obtain relevant weather data for all the provinces involved in the dataset. These variables included the following:
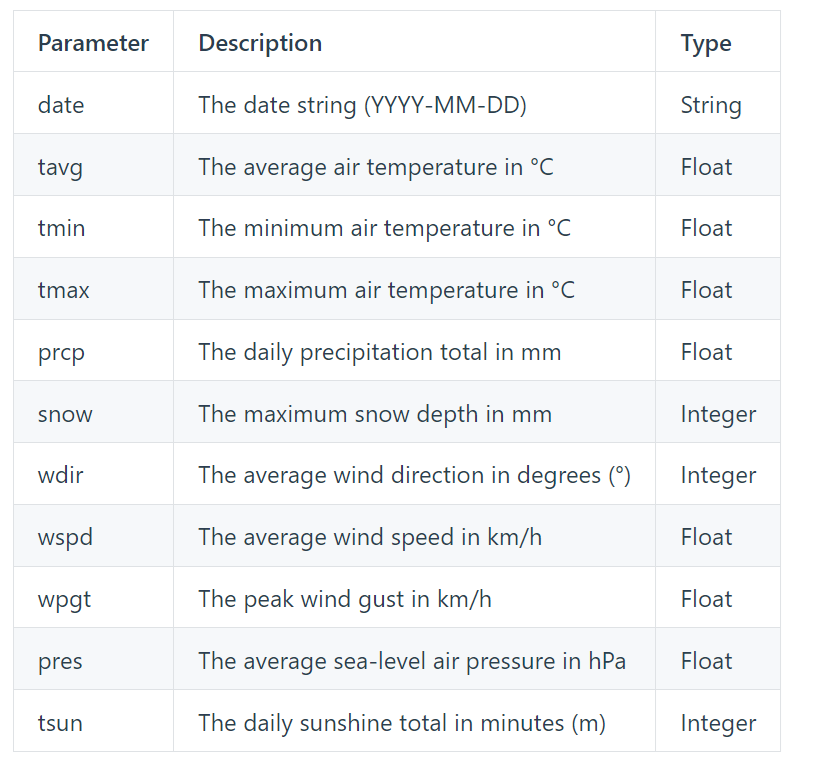
After doing relevant feature engineering, such as obtaining the cyclical component of date variables, and treating missing values, we proceeded with model training.
Model training
We trained 16 regression models to determine which one had the best fit against the negative RMSE. The final model selected was a CatBoostRegressor, which was trained with optimal hyperparameters using the Optuna library. The resulting model allows for accurate predictions of the frequency of car accidents over time and a better understanding of the factors that influence their occurrence.
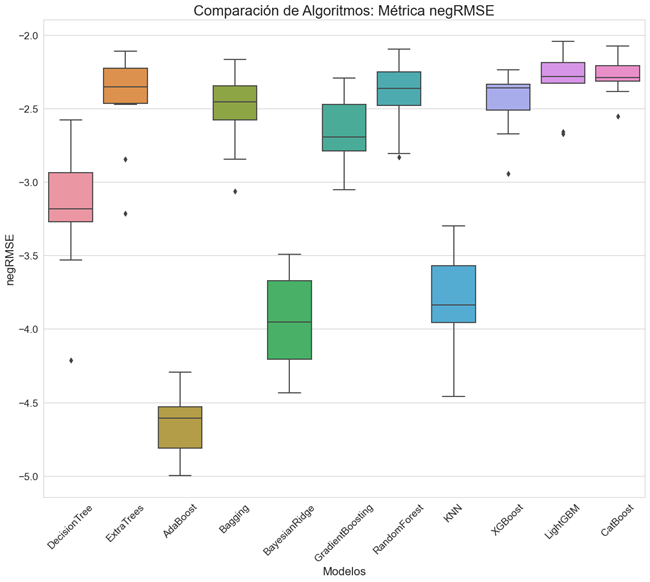
One of the most important findings in this study of the factors that influence the occurrence of car accidents, was that wind speed tends to be a very good predictor of such occurrences. Also, atmospheric pressure, and the longitude and latitude points. This variable importance was determined using SHAP values plots.
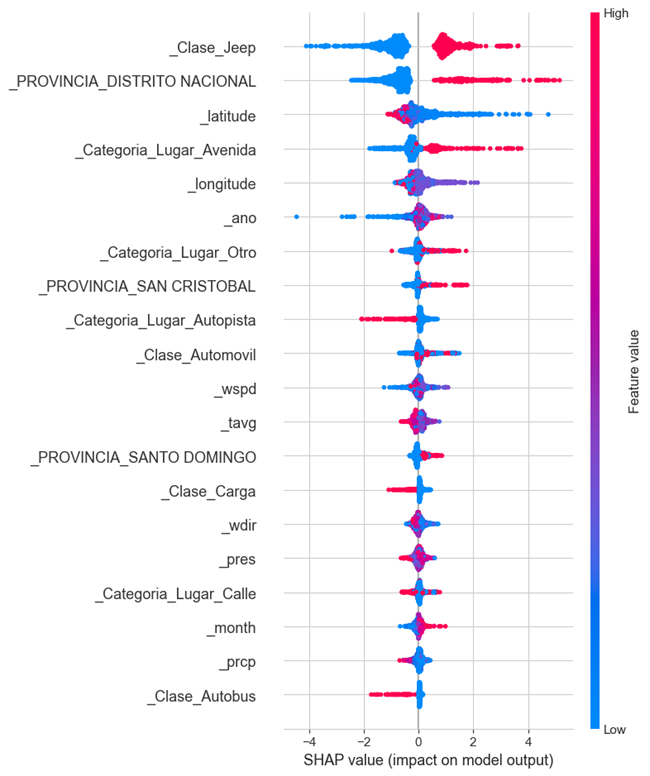
Results
We obtained the RMSE metric at 2.07%, with the CatBoostRegressor model. The R squared was determined at 0.86. We presented our findings, challenges, and recommendations, reaching second place in the data science competition.
You can find more about this project here. The code includes data cleaning and preprocessing, feature exploration, selection, and training of various machine learning models, as well as hyperparameter optimization.